Data Structures & Algorithms
Computer Organization
Input Unit
Aggregates information received from input peripherals and makes it available for further processing.
Output Unit
Takes processed data from the computer and makes it accessible externally.
Memory Unit
The volatile, fast-access memory makes data immediately available for processing when needed. Typically lost when power to the computer is interrupted.
Arithmetic and Logic Unit (ALU)
This "production" section performs calculations such as addition, subtraction, multiplication, and division. It allows the computer to compare data and determine whether they are equal or not.
Central Processing Unit (CPU)
This "administrative" section coordinates and supervises the operation of the other sections. It instructs when and how information should be processed by other parts of the processor.
Secondary Storage Unit
Preserves information even if power is lost, providing persistent data that can be accessed later. Examples include hard disk drives, DVDs, USB flash drives, etc.
Data Hierarchy
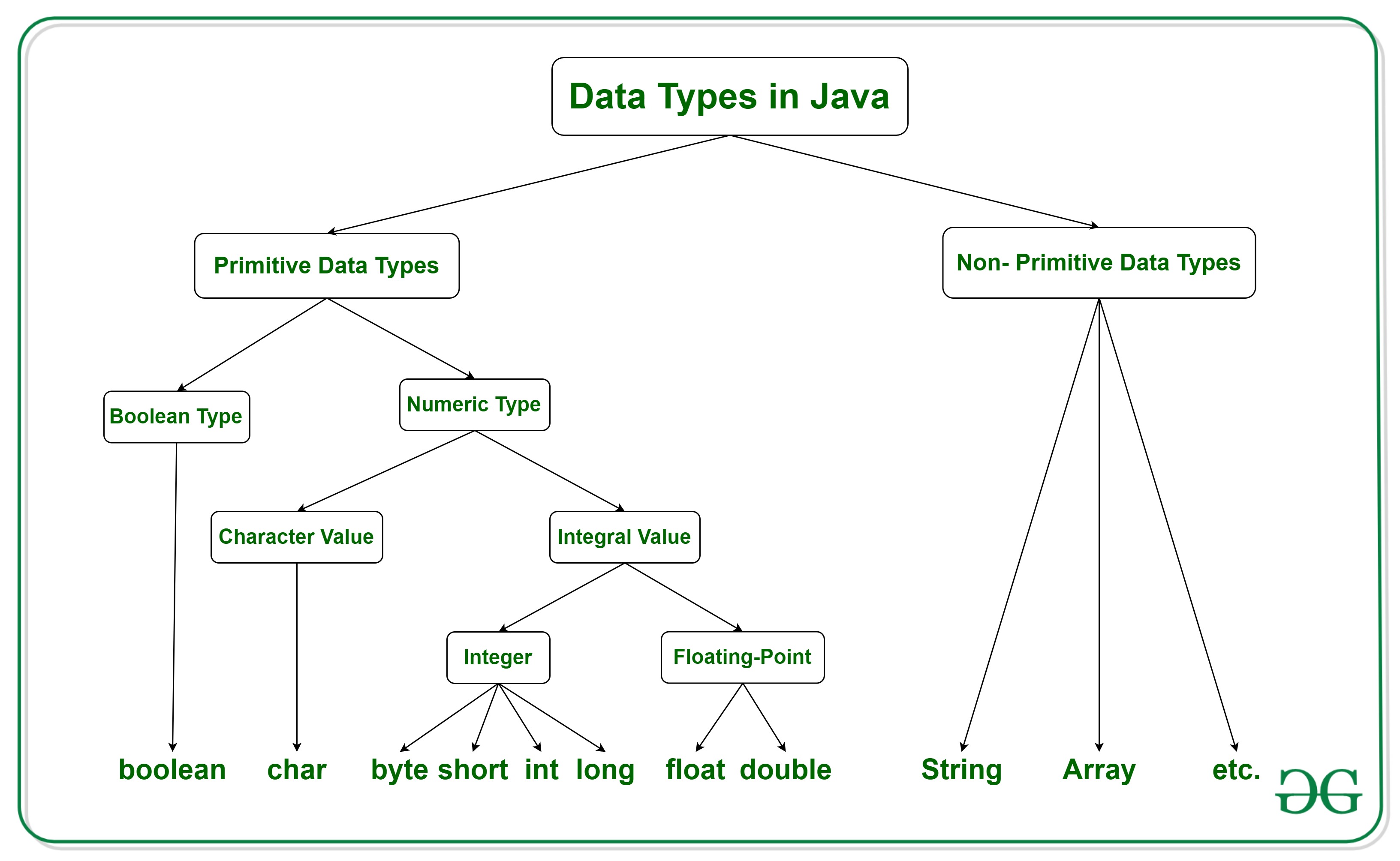
The organization of data that makes the structure of Java programs, to be seen later, occurs in an 'encapsulated' manner where each structure depends on the previous one to exist. And this is not only valid for Java but concerns how data is structured in computers in general.
Bits → Ultimately, all the complexity performed by computers is possible thanks to the first level of the data hierarchy: bits. Through the manipulation of 0 and 1, computers do everything we are accustomed to seeing. This is the closest "layer" to the hardware and can be associated with pulses of energy and their absence.
Characters → It would be humanly infeasible to make computers perform their operations directly by manipulating zeros and ones. Instead, we use standardizations such as decimal numbers and universally known symbols. This was done by associating each character with a sequence of zeros and ones.
Fields → Just as characters are composed of bits, fields are composed of characters or bytes. A field is a group of characters or bytes that convey meaning. For example, a field consisting of uppercase and lowercase letters can be used to represent a person's name, and a field consisting of decimal digits can represent a person's age.
Records → It is composed of several related fields. Taking a practical example of a program that stores employee data, the following fields would be required: Name, identification number, address, salary, annual income, amount of taxes withheld, etc. The grouping of these fields is called records.
Files → Just as records are composed of several aggregated fields, files are formed by engaging multiple records. In operating systems, the term "files" may receive a different treatment, but for didactic purposes, the initial explanation is sufficient.
Database → A collection of organized data for easy access. The most popular database model is known as a "Relational Database," where data is stored in simple tables. A table consists of records and fields. For example, a table of students may include fields such as name, surname, specialization, year, student ID, and average academic performance. The data for each student is a record, and the individual information in each record is the fields.
Big Data → Big data applications deal with these enormous amounts of data, and this field is growing rapidly.
Low-Level and High-Level Languages
The instructions that programmers write for computers can be roughly divided into three different types:
Machine Languages
Strings of numbers that are ultimately denoted as 0 and 1; this language makes the manipulation of important data humanly infeasible and renders programming impractical.
Assembly Languages
Rudimentary forms of converting essential operations into basic English terms, providing greater tangibility to programming. Assembler programs were developed to translate early programs into assembly languages so that the computer could understand them.
High-Level Languages
Single instructions performing substantial tasks. These languages help programmers write instructions that resemble everyday English and contain commonly used mathematical notations.
Compilers
Concept of Algorithm and Data Structure
In essence, the algorithm is the action-indicating verb, decision-making, the processing of commands, whereas data structures are responsible for organizing data in the most suitable way.
Overview, Practical of Algorithms:
A sequence of steps to reach a specific solution. Algorithms allow repetition according to a set condition. We also use algorithms to solve simple problems and make decisions in various contexts. Just as it is possible to solve problems in various ways (whether productive or not), this premise is also valid in the context of software programming.
Representation
Algorithms can be represented in different ways to understand their functioning. In practice, the following representation models are the most well-known:
- Flowchart — A graphic model using geometric shapes to represent each step of the algorithm.
- Natural Language — Portuguese, English, German, etc. | Admits ambiguity.
- Artificial Language — Java, Go, PHP, etc. | Does not admit ambiguity.
- Pseudo-Language — Merges aspects of natural and artificial languages.
Low-level and high-level languages: The "lower," the closer to the hardware; the "higher," the closer to humans.
Data Structure
Overview, Practical of Data Structures:
What are data structures: They aim to organize and manage data, giving structure to them. An example that can be taken is the list of approved candidates in a contest, where we have the students (data) and the ordering that arranges how they will be displayed on the list.
Thus, we understand that a "list" is a way of organizing data, so it can be taken as a data structure. Another example that can be given is the queue.
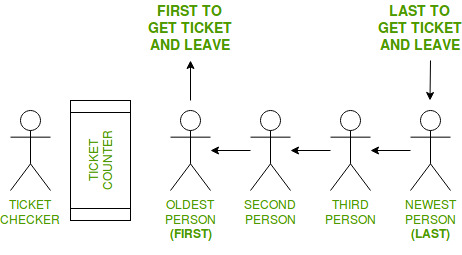
FIFO — First in First Out | The first to enter is the first to leave.
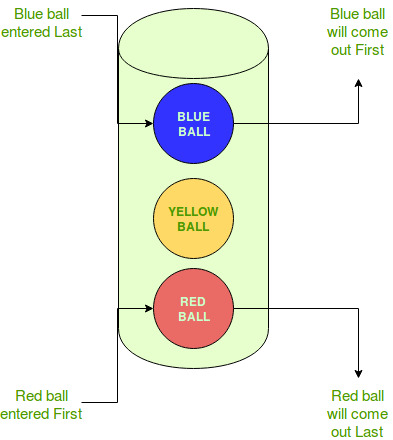
LIFO — Last in First Out | The last to enter is the first to leave.
We must ensure organization in everything we do. In practice, this means defining criteria and/or rules for certain data to be adherent or not to a structure. There are several models of data structures used, the most well-known are:
Stack Model
Tree Model — Commonly used in the file systems of operating systems and present throughout the web infrastructure.
Table Model — Organizing data through rows and columns.
Basic or Primary — int, real, string, bool, etc.